How to Deliver Business value with AI systems
Introduction
If you also want AI systems to deliver business value, you have come to the right place. To deliver proper business value there needs to be a deep understanding of how to create reliable systems that can consistently deliver value. Having a couple of machine learning models that do well on notebooks but can’t be put into production does the opposite.
In this post, we will talk about how to think about a system that can deliver business value using machine learning effectively.
Maturity of Machine Learning
To deliver value there is a need to understand where we stand and what we need to provide. There are multiple models of the Machine Learning Operations cycle that can help us understand this scenario. Out of the different maturity models, the Azure MLops maturity model is the one I could completely relate to in increasing order of complexity and milestones.
Since we are mostly concerned with designing machine learning systems in this post the emphasis from the Azure model is on the Model creation, Model release and application integration phase. The organization aspect of things isn’t covered in this post but is also a main pillar to ensure that there are teams of different strengths coming together to build a reliable system.
Since we are concerned with bringing a machine learning model to production the emphasis will be on Model creation, Model release and integration with the application. There is another aspect of building cross functional teams of various capacity which we will not delve into detail in this blog post as that is a post for another day.
The issues with most teams across the board is that data scientist generally come from a non engineering background and hence are required to learn skills beyond their paycheck and engineers need an understanding of machine learning which again exceeds their role capacity. The end result is that we have data scientist building a model and handing over to engineers to make it into deployable software into production.
While you can refer to the machine learning maturity model here and maybe look at the images below from here. I would go on to talk about stages of deployment.
Stages of Machine Learning deployment
Minimum Deployable Product:
Like in a startup where there is a minimum viable product on which there are iterations performed we should start thinking about Minimum deployable product which can get the customer some value and is a move towards the grand utopia of no manual intervention anywhere in the ML training cycle.
So let us start thinking about how to serve simple machine learning models into production first, the LLM world brings hardware challenges which is probably too much to aspire if the organisation hasn’t deployed even simple machine learning models.
We would have a machine learning model at this point in time this can be stored at a cloud storage location or at the server. The first step is to wrap an API with endpoints that can take requests and can then return an inference value of some meaning.
For example if the problem is a classification problem just returning a vector of 0 and 1 makes no sense to the end user. This API would do the conversion to possible categories and return value to the user that can be either consumed by the frontend client for display or by other services to do some processing.
In addition to the API we should add some testing in the code unit tests to ensure that functions work at an implementation level and integration tests so that we know that it works with the entire system. How to write these tests is not our main focus now. Add a CI pipeline where we can check for builds and tests in an automated fashion whenever we push code into the repository. This should offer some basic software testing reliability to a model that has not seen production.
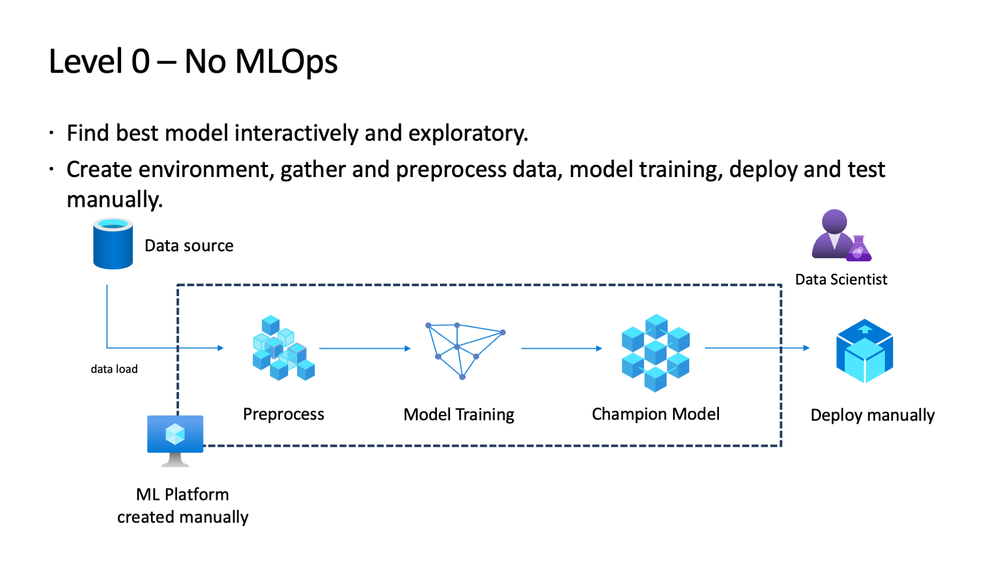
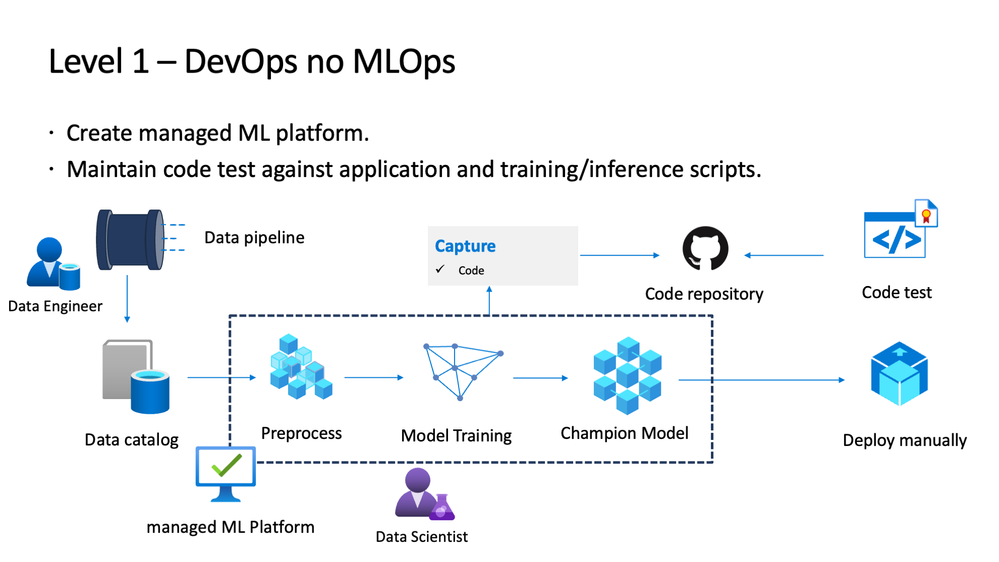
Automatic Retraining
Now that we have a minimum deployable version which is available as a containerised deployment in a container registry we should probably take a look at how can we achieve the next feat of making the retraining process smooth, so that in case of issues with the deployed model we can automatically get the data, perform pre-processing and then do a training of the model using the newer data.
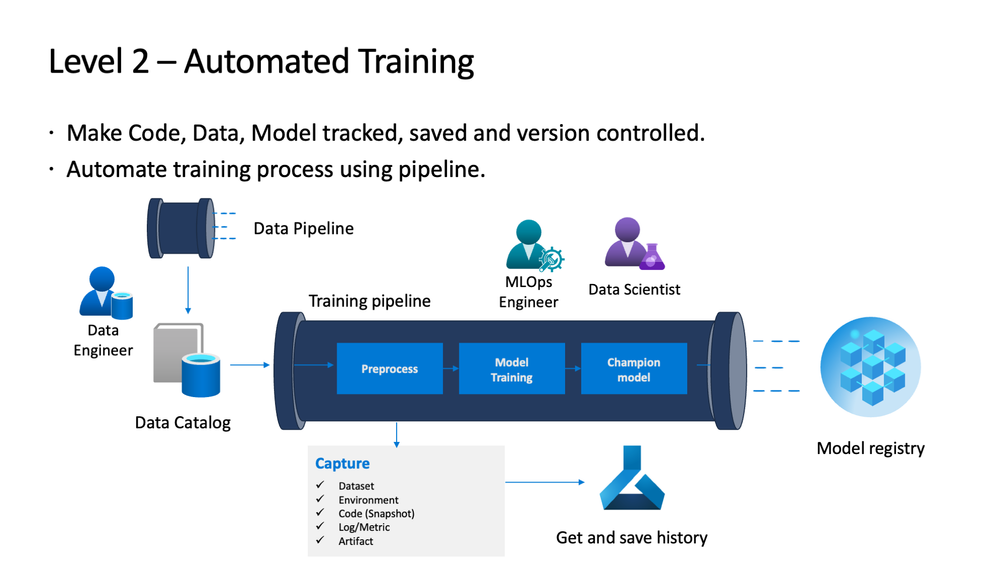
Let us take a look at some of the components and why they would be needed at this stage.
- Data Pipelines and data contracts: With data pipeline and data contracts we can fetch very reliable data that meets the input requirements of the model and the data contracts can ensure that this happens in a very type safe fashion.
- Data versioning: While we do retraining it is probably a good idea to maintain the version of the data using timestamps and other metadata requirements. Tools like DVC help us maintain versions and this is essential to create a reproducible training environment if there are issues with the training or any
- Training pipelines: Building Machine learning pipelines where it is probably good practice to use orchestration to run the preprocessing, training and testing as a part of single flow. By using orchestration tools we can modularize the code and recognize if there is any issues in a particular module.
- Model registry: Model registry can be thought of as a metadata store for models which can help version models, provide aliases, tag and annotate them, it provides an interface which solves when multiple versions and multiple models are produced by having something unique.
- Machine Learning monitoring: While a full fledged monitoring is not required an observability framework that can monitor the drifts in models, data is required and maybe an alerting system which can notify when the threshold of performance is declining can be present so that there is a manual intervention from the team on whether the models need to be retrained or not.
While these components can add complexity to the existing workflow it is necessary to remove obvious mistake when scale of model creation increases. The best way to approach this would be to have a team that can maintain these components as a ML platform and the data scientists can be their internal customer who can use the platform.
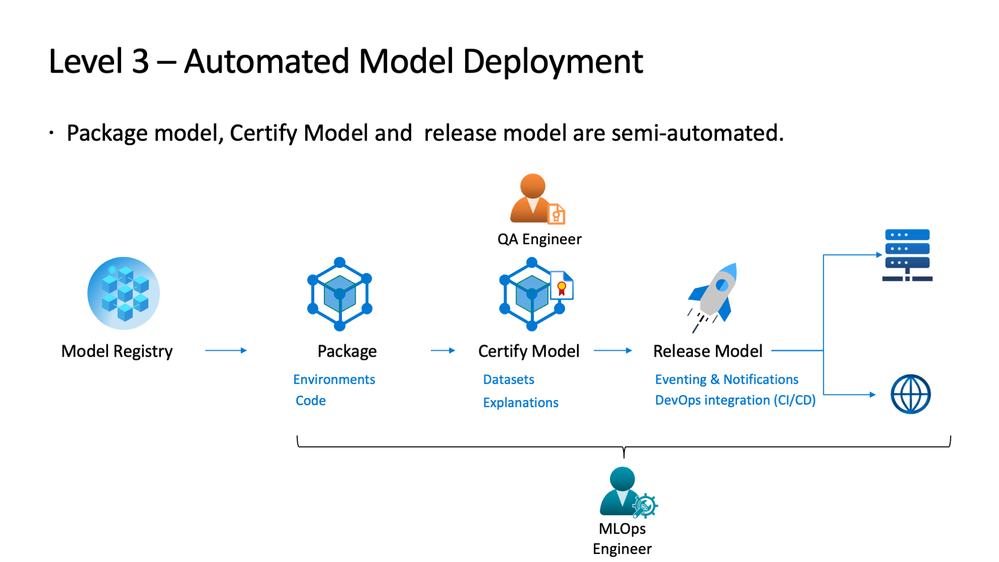
Complete Automatic Machine Learning pipeline
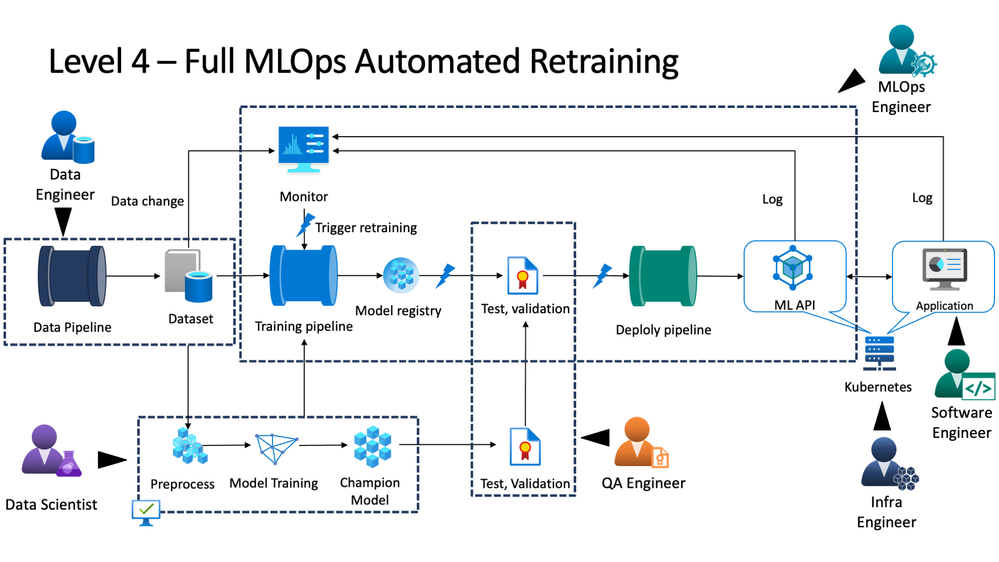
This stage is attained by very few companies where everything is automated and there is minimal manual involvement in making things work together. It is the utopia that people aim for when they start building an MLOps department. while there is minimal manual intervention needed in between components we would still need a team that can add or remove components perform some spring cleaning to keep the platform clean and technical requirements running up to data.
Conclusion
While the blog limits it within the maturity model, there needs to be a deep dive into each component and this can be extremely challenging. While MLOps is still not a matured field each deployment choice can have different effects on the end product. My aim with this article was to bring some thought into what are different stages and how a beginner can approach each stage depending on their specific requirements.
I havent covered the details of each component and that is something for the future. For starters I would recommend this blog series for building a minimum deployable product version and then the journey deepens quite a bit.