Algorithm for Private Data Analysis- Lecture 1
In the interest of learning about Differential privacy I was searching the web for a course that basically starts from very basic and explain differential privacy to me. In this lecture the main focus was on what were the practices that led to a loss in privacy and certain real life examples to initiate people to the world of DP. There is also a gentle introduction into world of Data attacks. In the end of the lecture K-Anonymity is introduced.
NYC Taxicab data
Background Using Freedom of Information Law request one could get access to the NYC taxicab data.It is similar to Right to Information act (RTI) in India. The dataset is now public here. If you are a story person like me Please read this story about how the data was obtained.
Alarm bells about data A sample row from dataset with corresponding field is shown below
medallion, hack license,vendor id,rate code,store and fwd flag,pickup datetime,dropoff datetime,passenger count,trip time in secs,trip distance,pickup longitude,pickup latitude,dropoff longitude,dropoff latitude
6B111958A39B24140C973B262EA9FEA5,D3B035A03C8A34DA17488129DA581EE7,VTS,5,,2013-12-03 15:46:00,2013-12-03 16:47:00,1,3660,22.71,-73.813927,40.698135, -74.093307,40.829346
This shows some sensitive information despite being anonymized. If we can find out the driver we can figure out details of the trips and income based on that. The Data owners have tried to anonymize that. Based on this analysis we find that this anonymization is not enough. The inspiration for the above post started here. The post found out that one driver was earning a lot of money. But according to the analysis post we found that the MD5 hash of number 0 gives the suspicious earning member’s medallion number. This doesn’t itself give any information about the driver but passing the MD5 hash of other drivers could give away the medallion numbers. With other publicly available dataset we can easily match the data and get the names and the incomes and location. This is a massive privacy violation.
A simple way to avoid this would be to generate random identifiers for the medallions. But this can also be prone to attacks.
Netflix Prize
Background Netflix hosted a competition between 2006 and 2009 challenging scientists to improve their recommendation. The winner of the contest is a team called BellKor’s Pragmatic Chaos which used matrix factorization technqiues to win the most coveted $1,000,0000 prize money. The dataset provided for this competition also has anonymization but it was difficult and could go wrong very easily prone to attacks similar to previous case where we can get a corresonding public dataset.
Dataset The dataset can be found now in kaggle competition here. The dataset consists of mainly of an Anonymized USERID, MOVIEID, Rating and Date. In this paper they perform a de-anonymization of the dataset by associating it with a public IMDb dataset.
De-Anonymization
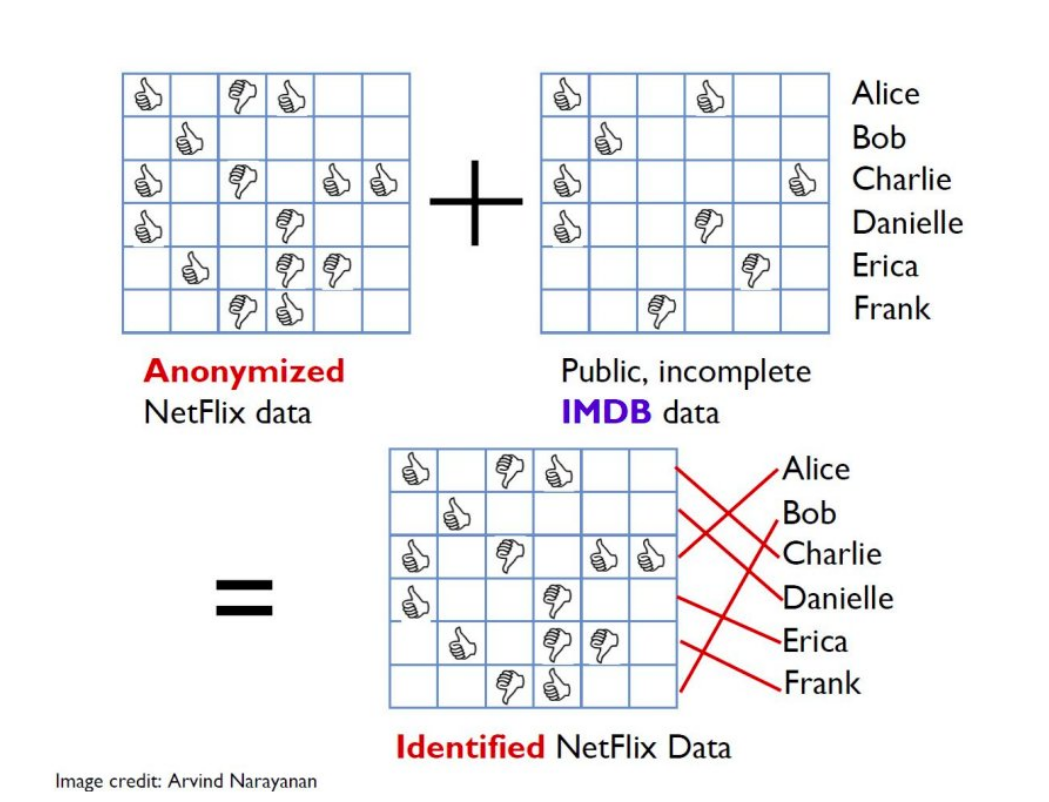 The approach by Narayanan et.al involved usage of a public IMDb dataset and matching users based on similar rating provided in the IMDb dataset. Such a weak matching can also lead to names or user handles of many users across both the datasets. This is a very frightening case and a clear loss of privacy in the data.
The approach by Narayanan et.al involved usage of a public IMDb dataset and matching users based on similar rating provided in the IMDb dataset. Such a weak matching can also lead to names or user handles of many users across both the datasets. This is a very frightening case and a clear loss of privacy in the data.